


光学学报 丨 2024-01-11
分布式光纤传感技术研究和应用的现状及未来中国激光 丨 2024-01-24
光量子精密测量研究进展(特邀)光学学报 丨 2024-02-23
水下轨道角动量光通信中国激光 丨 2024-01-24
超构表面:设计原理与应用挑战(特邀)激光与光电子学进展 丨 2024-01-29
窄线宽激光技术研究进展(特邀)加州大学洛杉矶分校Samueli工程学院开发了一种计算机视觉系统,可以根据人类使用的相同视觉学习方法识别物体。该系统可以说是计算机视觉的进步,也是迈向通用人工智能(AI)系统的一步,也就是说,自己学习的计算机系统是直观的,基于推理做出决策,并以更人性化的方式与人类互动。
当前的计算机视觉系统不是为了自己学习而设计的。他们必须接受有关学习内容的训练,通常是通过查看成千上万的图像来识别他们试图识别的对象。

加州大学洛杉矶分校开发的计算机视觉系统可以仅基于部分视觉来识别物体,例如,通过使用摩托车的这些照片片段。由加州大学洛杉矶分校Samueli提供。
UCLA系统采用三步法。首先,它将图像分成小块,研究人员将其称为“视图块”。其次,它学习这些视图块如何组合在一起形成相关对象。然后,它查看周围区域中的其他对象,以及这些对象是否与描述和识别主对象相关。
为了帮助新系统更像人类学习,工程师将其沉浸在人类生活环境的互联网复制品中。“幸运的是,互联网提供了两件有助于大脑启发的计算机视觉系统以与人类相同的方式学习的东西,”Vwani Roychowdhury教授说。“一个是丰富的图像和视频,描绘了相同类型的对象。第二个是这些物体从许多角度展示-模糊,鸟瞰,近距离-它们被放置在不同的环境中。
研究人员从认知心理学和神经科学的发现中深入了解了语境学习。“情境学习是我们大脑的一个关键特征,它有助于我们构建强大的对象模型,这些模型是集成世界观的一部分,其中所有东西都是功能连接的,”Roychowdhury说。
UCLA系统为对象原型的无监督学习提供了可扩展的框架,使得能够从它们的不同配置和视图以及它们的空间关系中识别可变形对象。在计算上,对象原型被表示为几何关联网络。
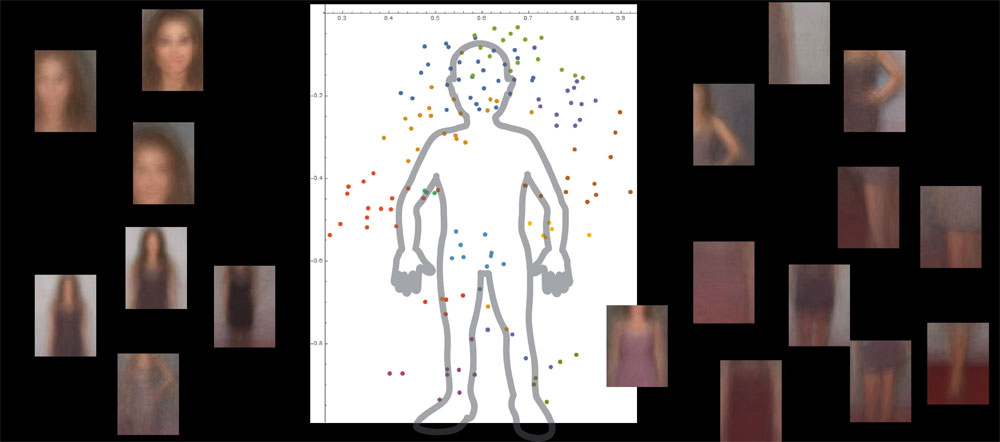
该系统通过查看人体中的数千个图像然后忽略非必要的背景对象来了解人体是什么。由加州大学洛杉矶分校Samueli提供。
研究人员用大约9000张图像对系统进行了测试,每张图像都显示人和其他物体。该系统能够在没有外部指导且没有标记图像的情况下构建人体的详细模型。研究人员使用摩托车、汽车和飞机的图像进行了类似的测试。在所有情况下,他们的系统表现得更好,或者至少与通过多年训练开发的传统计算机视觉系统一样好。
该研究发表在美国国家科学院院刊(https://doi.org/10.1073/pnas.1802103115)。
论文链接本文受译者委托,享有该文的专有出版权,其他出版单位或网站如需转载,请与本站联系,联系email:mail#opticsjournal.net。(为防止垃圾邮件,请将#换为@)否则,本站将保留进一步采取法律手段的权利。


报名通知")


