1 浙江大学信息与电子工程学院,浙江 杭州 310027
2 浙江大学宁波理工学院,浙江 宁波 315100
3 之江实验室,浙江 杭州 310027
由于光传输具备高通量、低延迟、低能耗等优势,光学神经网络有望应对目前人工智能技术发展中所面临的能耗和计算效率的挑战,成为近年来学术界和工业界的研究热点。光学神经网络的目标在于用光子作为物理载体构建人工神经网络算法中的基本计算单元,从而实现高性能的新型计算架构,并将其应用于实际问题的解决。本综述介绍了光学神经网络中关键光子器件的工作原理和特点、系统架构特征与应用场景。在跟踪大量国内外研究进展后,进一步分析了光学神经网在系统实现上所面临的挑战及发展趋势。
光计算 光学神经网络 线性矩阵计算 非线性激活器 激光与光电子学进展
2023, 60(6): 0600001
Author Affiliations
Abstract
State Key Laboratory of Advanced Optical Communication Systems and Networks, Intelligent Microwave Lightwave Integration Innovation Center (iMLic), Department of Electronic Engineering, Shanghai Jiao Tong University, Shanghai 200240, China
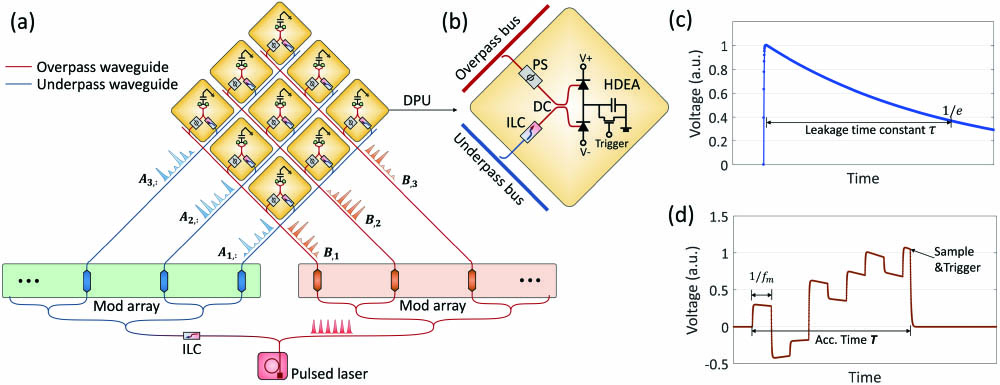
We propose an optical tensor core (OTC) architecture for neural network training. The key computational components of the OTC are the arrayed optical dot-product units (DPUs). The homodyne-detection-based DPUs can conduct the essential computational work of neural network training, i.e., matrix-matrix multiplication. Dual-layer waveguide topology is adopted to feed data into these DPUs with ultra-low insertion loss and cross talk. Therefore, the OTC architecture allows a large-scale dot-product array and can be integrated into a photonic chip. The feasibility of the OTC and its effectiveness on neural network training are verified with numerical simulations.
optical tensor core neural network training matrix multiplication homodyne detection dual-layer waveguides Chinese Optics Letters
2021, 19(8): 082501
中国科学院上海技术物理研究所, 上海 200083
图像配准是一项基本而又非常关键的图像预处理技术。在很多应用领域, 要求配准精度达到亚像素级。现有的相位相关法具有精度高、计算简单等特点, 但是随着图像规模的增大, 计算付出的时间代价是巨大的。本文提出基于 SURF和矩阵乘法相位相关法的超大规模遥感图像亚像素配准算法, 采用化整为零的方法, 首先把整幅图像划分成不同区域, 其次使用改进的 Canny算法进行边缘分割, 去除无用信息, 再次使用 SURF算法提取特征, 最后在关键点周围使用矩阵乘法相位相关估计图像亚像素偏移量。实验表明本文提出的算法不仅提高了算法运行速度, 同时也解决了图像尺寸太大导致一般计算机无法处理的问题。并且由于矩阵乘法相位相关的良好抗噪声特性, 因此即使存在噪声, 算法仍然可以获得较高的亚像素偏移量估计精度。
图像配准 SURF算法 矩阵乘法相位相关 亚像素 image registration SURF algorithm matrix multiplication phase correlation sub-pixel
1 中国科学院光电技术研究所微细加工光学技术国家重点实验室, 四川 成都 610209
2 中国科学院大学, 北京 100049
针对目前实现光场传输的两种算法无法同时满足运算速度和精细度的问题,提出了矩阵相乘算法,阐明了其实现思想,推导了其实现过程。结合激光相干合束实例进行了仿真分析,结果表明,对于六路高斯光束的相干合束,快速傅里叶变换算法耗时短,但无法得到精确的计算结果;积分算法和矩阵相乘算法均可获得远场准确的光强分布,但积分算法需耗时15.7 h,而矩阵相乘算法仅需2 s,提高了运算效率。证明了矩阵相乘算法具有快速、准确的优点。
衍射 光场传输 矩阵相乘 运算速度 精细度 相干合束
1 中国科学院长春光学精密机械与物理研究所, 吉林 长春 130033
2 中国科学院大学, 北京 100049
为了解决大口径光学元件磁流变高精度加工问题,基于矩阵运算模型,提出了SBB(Subspace Barzilai and Borwein)最小非负二乘与自适应Tikhonov正则化相结合的驻留时间快速求解方法。同时,在一次收敛中采用双去除函数优化螺旋线轨迹下光学元件的加工,保证中心区域与全口径面形精度一致。仿真表明该算法与常用Lawson-Hanson最小非负二乘法相比,计算精度一致且求解效率大幅提高。对Φ600 mm以彗差为主的光学表面模拟加工,峰谷(PV)值和均方根(RMS)值从初始的2.712λ与0.461λ中心区域全局一致收敛到0.306λ和0.0199λ(λ=632.8 nm)。因此,提出的算法能够在有效保证面形收敛精度的同时快速获得稳定可靠的驻留时间分布,为磁流变抛光应用于大口径光学元件提供有力支持。
光学制造 驻留时间 矩阵运算 全局收敛 磁流变抛光
国防科学技术大学理学院, 湖南 长沙 410073
离散傅里叶变换是数字信号处理中最核心的数学工具之一。传统基于数字电路的离散傅里叶变换方法受限于电子器件的速度,难以满足高速信号处理要求,尤其制约了太比特每秒超高速光处理技术的发展。基于并行光学向量矩阵乘法器原理的离散傅里叶变换方法,利用光传播的高速和低损耗特点,提出以相位空间光调制器为核心变换矩阵的全光并行离散傅里叶变换方法,并通过实验进行了验证。实验结果显示,所提出的全光并行离散傅里叶变换误差小于0.13,通过进一步的模块集成和性能提升,该方法将在高速光信号处理中有较大的应用潜力。
傅里叶光学 离散傅里叶变换 相位空间光调制器 并行光学向量矩阵乘法 中国激光
2012, 39(s2): s209002
本文提出一种用于迭代法求解线性方程组的光电混合系统。该系统的光学部分主要由单个全息透镜组成,它执行矩阵与矢量的乘法运算;系统的其余部分执行矢量的测量与求和,它由CCD探测器件和一台微机组成。使用这个光电混合系统,用迭代法对一个4元线性方程组求解,实验结果与理论解比较,误差约为5%。
光电混合处理器 矩阵乘法 解线性方程组
本文利用LiNbO3:Fe晶体中的四波混频完成了矩阵-矢量和矩阵-矩阵乘法运算。代表矩阵元素的光点强度小于10OμW/mm2,响应时间为秒的量级。文中还讨论了两个影响运算精度的光折变效应。
光折变非线性 四波混频 矩阵相乘









